TL;DR: We identify Relevant Visual Information Shift (RVIS) as the primary reason visual token pruning fails on reasoning tasks, and propose DSTP, a training-free add-on that adaptively swaps visual tokens during decoding to restore reasoning performance with minimal overhead.
Abstract
DSTP: Adaptive Token Pruning for Visual Reasoning
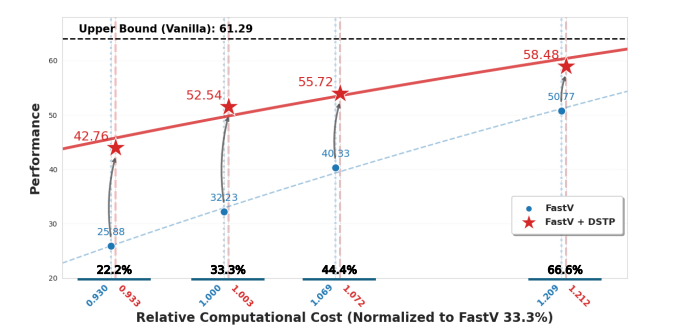
Figure. DSTP at 33.3% token retention outperforms vanilla FastV at 66.6% with significantly less computational cost, demonstrating that providing the right tokens at the right time matters more than simply retaining more tokens.
Recently, visual token pruning has been studied to handle the vast number of visual tokens in Multimodal Large Language Models. However, we observe that while existing pruning methods perform reliably on simple visual understanding, they struggle to effectively generalize to complex visual reasoning tasks, a critical gap underexplored in previous studies.
Through a systematic analysis, we identify Relevant Visual Information Shift (RVIS) during decoding as the primary failure driver. To address this, we propose Decoding-stage Shift-aware Token Pruning (DSTP), a training-free add-on framework that enables existing pruning methods to align visual tokens with shifting reasoning requirements during the decoding stage.
Extensive experiments demonstrate that DSTP significantly mitigates performance degradation of pruning methods in complex reasoning tasks, while consistently yielding performance gains even across visual understanding benchmarks.
Motivation: Why Does Pruning Fail at Visual Reasoning?
Pruning works for VQA, but fails for Visual Math Reasoning
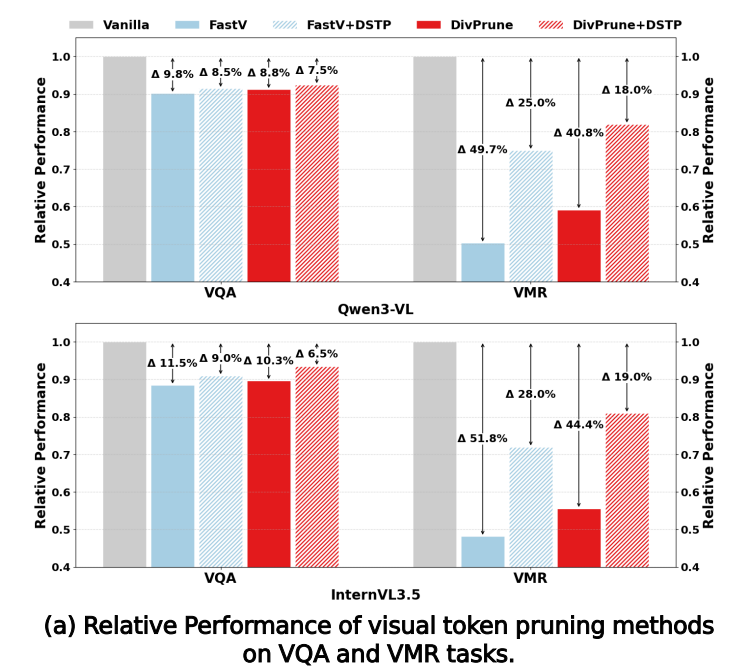
Figure 1(a). Performance retention rates of pruning methods on VQA vs. VMR.
We evaluate prominent pruning methods (FastV, DivPrune) on state-of-the-art MLLMs (Qwen3-VL, InternVL3.5) across VQA and Visual Math Reasoning (VMR) benchmarks. While pruning methods effectively preserve performance on VQA, they exhibit precipitous performance drops on VMR.
This consistent decline on VMR suggests that existing pruning methods fundamentally struggle to generalize to complex visual reasoning, despite their strong performance on simple visual understanding tasks.
Visual Focus Shift during Reasoning
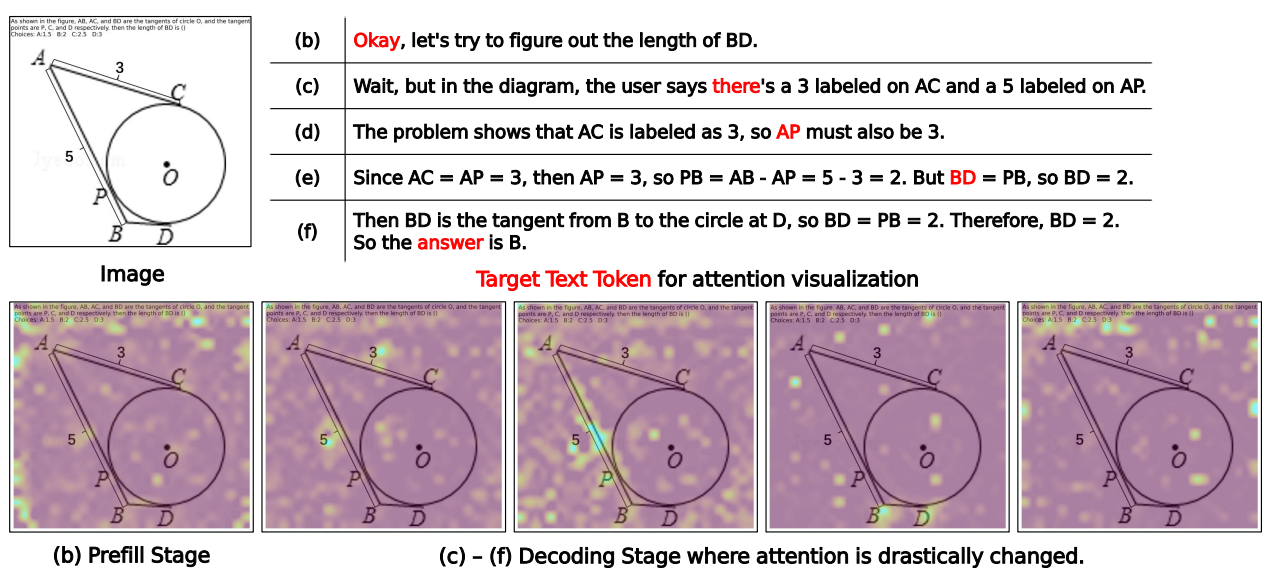
Figure 1(b)–(f). Attention heatmaps for a MathVerse sample on Qwen3-VL. The model's visual focus shifts drastically across decoding steps, reflecting the changing reasoning context.
Visual focus shifts during reasoning
By visualizing attention heatmaps at different decoding steps, we discover that the model's visual focus does not remain fixed on regions identified during the prefill stage. Instead, it dynamically transitions to entirely different visual areas to align with each successive reasoning step — a phenomenon we term Relevant Visual Information Shift (RVIS).
Diagnosing RVIS: A Hallmark of Visual Reasoning
We conduct a systematic analysis to characterize RVIS and establish it as the primary failure driver of existing pruning methods.
Finding 1 — RVIS Exists in Reasoning
Attention Stability Diverges between VQA and VMR
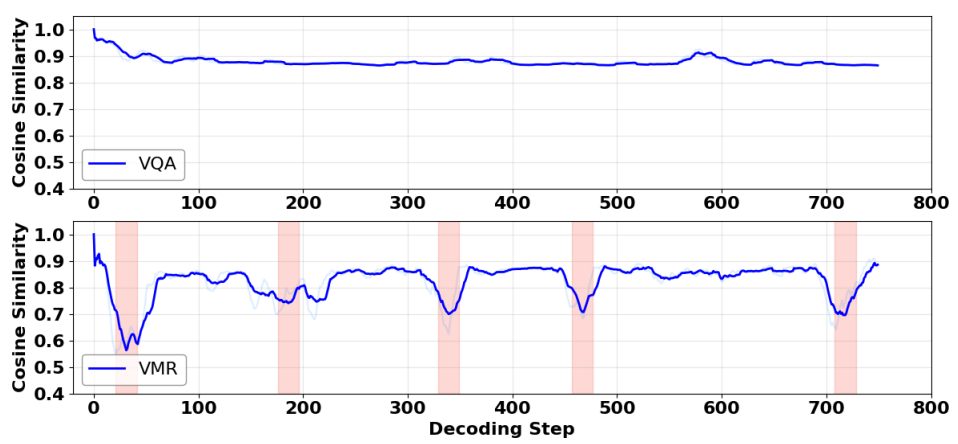
We track the cosine similarity between the visual attention at the prefill stage and each decoding step. VQA maintains high similarity throughout, while VMR exhibits sharp declines, revealing that the model frequently re-focuses on different visual regions during reasoning.
Figure 2. (a) Cosine similarity of visual attention between prefill and each decoding step. (b) Proportion of samples maintaining attention similarity above thresholds.
Finding 2 — Reasoning-Intrinsic Nature
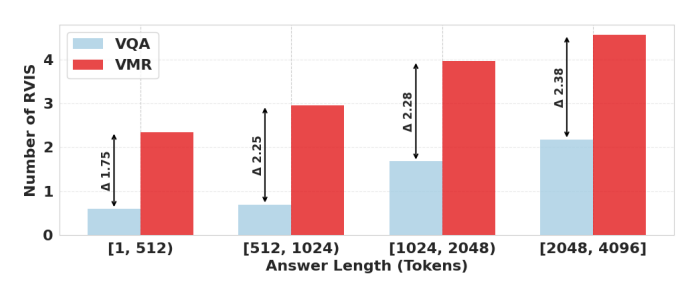
RVIS Is Not a Side Effect of Longer Generation
Even the shortest VMR samples (1–512 tokens) exhibit higher RVIS frequency than the longest VQA samples (2048–4096 tokens). This confirms RVIS as an inherent hallmark of the reasoning process, not a mere side effect of generation length.
Figure 3. Average RVIS occurrences across various answer lengths.
Observation
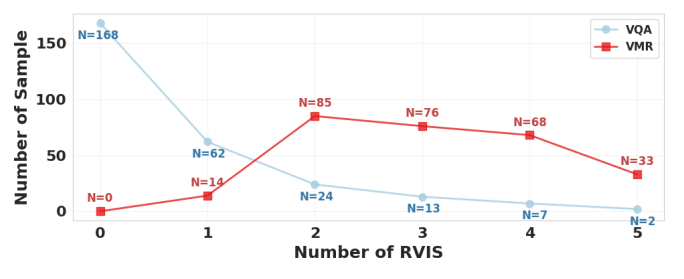
RVIS Frequency Distribution
VQA samples are largely static with zero RVIS, while VMR samples exhibit two or more shifts during decoding.
Figure 4. Distribution of RVIS occurrences for VQA and VMR.
Impact
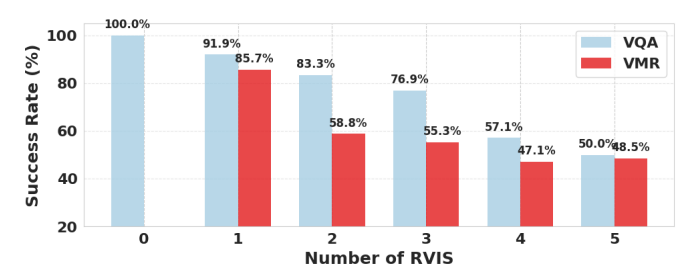
Pruning Success Drops with RVIS
The success rate of pruning methods drops precipitously with increasing RVIS frequency, providing direct evidence of the causal link.
Figure 5. Success rate of FastV across different RVIS frequencies.
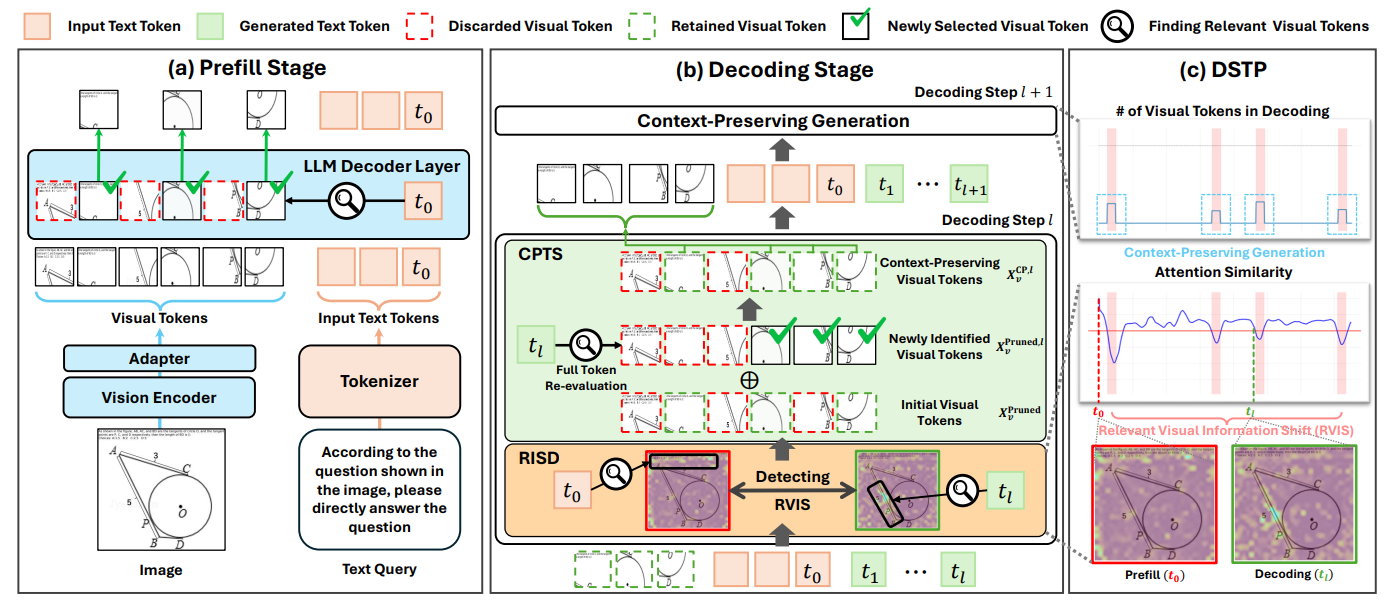
DSTP: Decoding-stage Shift-aware Token Pruning
Based on our analysis, we propose DSTP, a training-free and simple add-on framework that enables existing pruning methods to adaptively update visual tokens during decoding.
Module 1
RISD: Relevant Visual Information Shift Detect
Monitors visual attention similarity at each decoding step. When similarity drops below threshold τ, RVIS is detected and CPTS is triggered.
Module 2
CPTS: Context-Preserving Visual Token Swap
Re-evaluates all visual tokens (including discarded ones) and forms a union set that preserves original context while incorporating newly relevant tokens.
DSTP Framework Overview
Figure 6. Overall framework of DSTP. (a) Prefill-stage protocol. (b) RISD monitors attention similarity, invoking CPTS when RVIS is detected. (c) Overall flow throughout the decoding process.
Main Results
Visual Reasoning Benchmarks
DSTP is evaluated as a plug-and-play add-on to three pruning methods (FastV, DivPrune, VisionZip) on Qwen3-VL-4B and InternVL3.5-8B.
Method
MathVerse
WeMath
DynaMath
LogicVista
MMMU-Pro
Acc.(%)
Qwen3-VL-4B — Retain 33.3% Tokens
Vanilla (Full Tokens)
61.29
48.29
66.48
49.22
37.63
100%
FastV
32.23
25.90
38.76
30.64
19.41
55.7%
w/ DSTP
52.54
42.19
51.00
41.16
30.52
82.9%
DivPrune
33.90
29.32
41.94
30.64
13.08
55.2%
w/ DSTP
50.25
42.95
57.70
42.70
28.03
83.8%
VisionZip
36.80
35.57
43.16
29.53
16.36
60.4%
w/ DSTP
50.76
43.62
52.95
39.22
27.39
81.0%
Visual Understanding Benchmarks
DSTP also consistently yields performance gains on VQA tasks.
Method
SQA
VQAT
GQA
Acc.(%)
Vanilla (Full Tokens)
93.42
81.57
61.82
100%
FastV
87.98
74.82
60.04
94.3%
w/ DSTP
91.84
77.95
60.93
97.5%
DivPrune
86.12
71.36
58.07
91.2%
w/ DSTP
91.36
74.11
60.42
95.5%
VisionZip
90.41
77.10
60.68
96.5%
w/ DSTP
92.08
77.20
61.27
97.4%
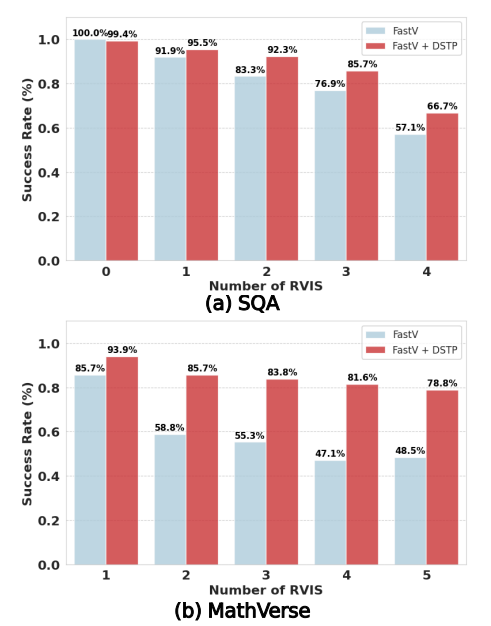
Robustness to RVIS: DSTP vs. FastV
Figure 7. DSTP yields consistent gains across all RVIS frequencies, with the gap widening as RVIS becomes more frequent.
In-Depth Analysis
Effect of Components: RISD & CPTS
Row
Detect
Swap Strategy
Ratio
MathVerse
MMMU-Pro
(a)
Full visual tokens
100%
61.29
37.63
(b)
FastV (33.3%)
33.3%
32.23
19.41
(c)
Random
CPTS
38.1%
37.69
22.36
(d)
Avg
CPTS
38.1%
51.51
27.68
(e)
RISD
Full
100%
53.04
29.55
(f)
RISD
Hard
33.3%
45.05
27.26
(g)
RISD
Merge
33.3%
47.58
28.38
(h)
RISD
CPTS
38.1%
52.54
30.52
Computational Efficiency
Despite DSTP's dynamic detect-and-swap mechanism, the additional TFLOPs overhead is negligible. Remarkably, DSTP at 33.3% retention surpasses vanilla FastV at 66.6% while requiring significantly less computation.
Qualitative Comparison
Visual Token Selection Visualization
Figure 9. DSTP successfully retrieves essential visual context that remains pruned even by the 66.6% static baseline (red tokens).
Qualitative Examples
We compare DSTP with FastV across diverse visual reasoning scenarios, illustrating how adaptive token swapping during decoding helps the model capture the precise visual features needed at each reasoning step.
Example 1. Robustness in numeric information extraction. DSTP maintains high fidelity in reading numerical figures where FastV exhibits semantic drift.
Citation
If you find this work helpful, please consider citing:
@misc{kim2026visualtokenpruningfails,
title={Why and When Visual Token Pruning Fails? A Study on Relevant Visual Information Shift in MLLMs Decoding},
author={Jiwan Kim and Kibum Kim and Wonjoong Kim and Byung-Kwan Lee and Chanyoung Park},
year={2026},
eprint={2604.12358},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2604.12358}
}